Specialized in...
Custom Web Scraping for
E-commerce & Social Platforms
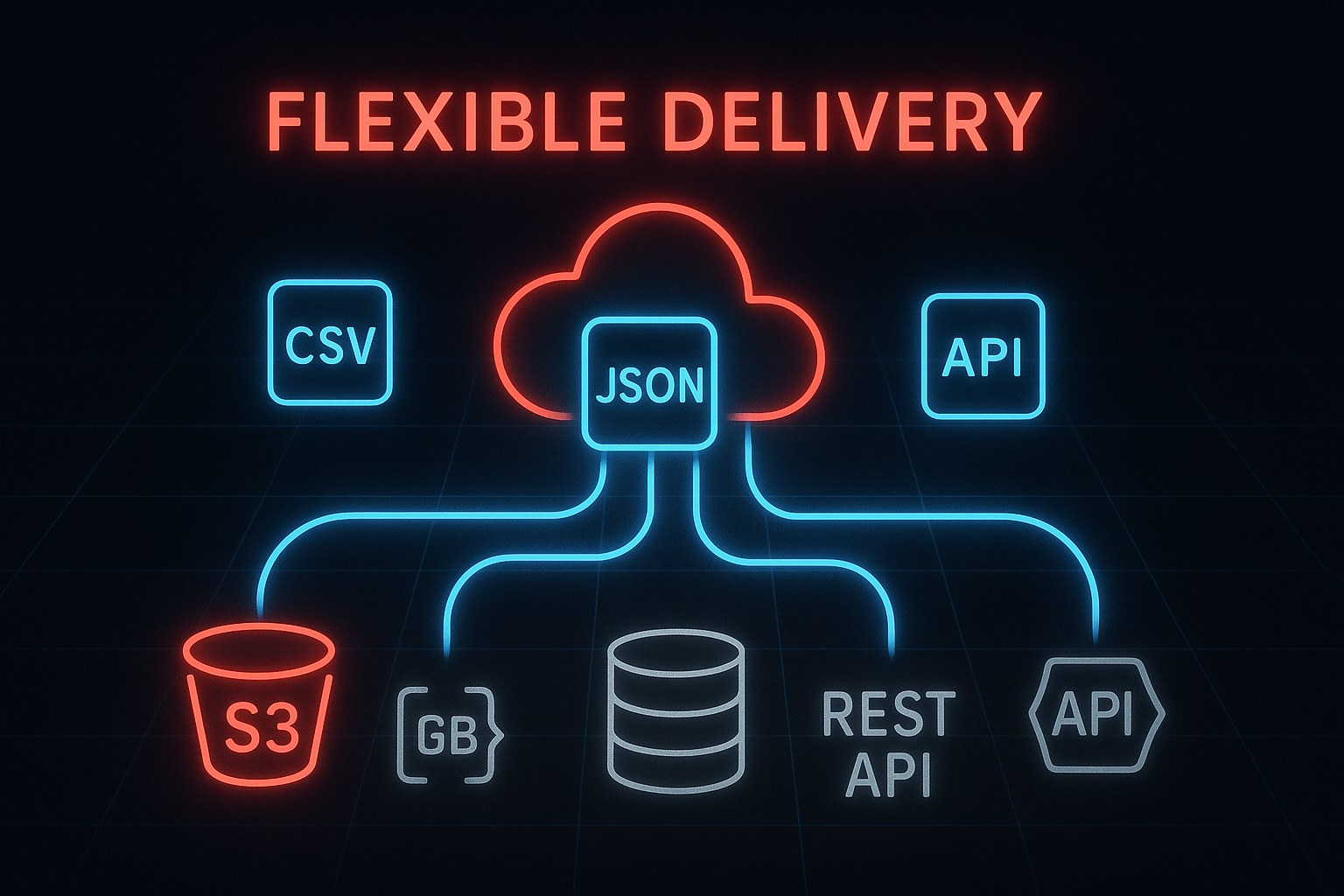
Collect real-time product data, track prices, and analyze social trends with tailored scraping solutions designed for e-commerce and social platforms.
We can also provide custom job market and real estate data.
Request a quote Learn more